기사본문
[김태형의 게놈이야기]구글·브로드硏의 '유전체+딥러닝'
입력 2018-05-29 10:28 수정 2018-05-29 10:28
김태형 테라젠이텍스 이사
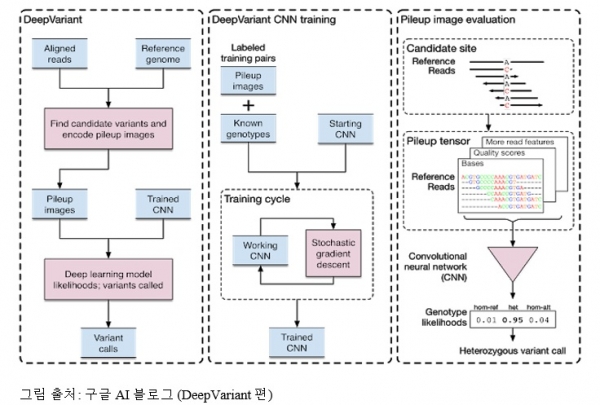
2017년 12월 구글 브레인(Google Brain) 유전체팀의 마크 데프리스토(Mark DePristo)는 구글의 생명과학부문인 베릴리(Verily Life Sciences)와 공동으로 2년간 연구 개발을 통해 만든 딥베리언트(DeepVariant)를 공식적으로 발표하고 논문과 프로그램 소스까지 모두 공개했다. 딥베리언트는 이름에서 알 수 있듯 차세대 유전체해독(Next Generation Sequencing) 데이터의 전체 분석과정 중 마지막 단계인 변이를 결정하는 부분에 적용되는 툴(tool)이다.
이 툴은 텐서플로우(TensorFlow) 기반의 이미지 분류 모델을 적용해 고양이와 개 얼굴을 정확하게 구분하듯 생명체가 가지고 있는 유전자 변이들을 정확하게 구분하고 맞추기 위해 개발되었다. 유전형을 알고 있는 수천만 개의 서열 이미지 데이터를 이용해 CNN(convolutional neural network)을 적용, 데이터 셋을 학습했다. 그 결과, 변이를 결정할 때 에러율을 50%이상 감소시켰다고 한다.
또 다른 비슷한 사례로 MIT와 하버드가 합작한 브로드 연구소를 들 수 있다. 브로드 연구소는 2018년 5월 자신들의 블로그에 딥러닝을 이용한 툴을 발표했다. 이 툴은 NGS 데이터 분석에 있어 전 세계에서 가장 많이 사용하고 있는 툴 중의 하나인 GATK에 딥러닝 기술을 적용한 것이었다.
이미 GATK는 머신 러닝 기반으로 개발되어 성능이 매우 뛰어난 툴로 알려져 있으며 전세계적으로 병원을 비롯해 대부분의 연구자가 유전체 분석 파이프라인에 채택해 널리 사용하고 있다. 이번에 브로드 연구소는 기술을 발전시켜 딥러닝 기술 중의 하나인 2D CNN을 적용해 variant recalibration(VQSR)의 삽입/결실(indel) 변이 콜링의 정확도를 30%나 향상시켰다. 보통 "technical artifacts"로 인해 삽입/결실(indel) 변이를 콜링할 때 에러가 많이 발생하는데 이 문제를 가볍게 해결한 것이다. 더 나아가 몇달내 더 개선된 GATK 업그레이드 버전을 발표할 예정이다.
사람들이 인공지능이라는 단어를 가장 직접적으로 인지한 사건은 아마 2016년 알파고와 사람의 바둑 대결일 것이다. 알파고가 지구상의 모든 인간 보다 바둑을 잘 둔다는 사실을 직접 확인한 이후로 인공지능의 가능성이 대두되었다. 그 이후로 컴퓨터를 전공하는 대학생들의 딥러닝에 관심을 가지고 다양한 문제에 적용하고 있는 것을 흔히 보곤 한다. 그리고 구글 번역기와 네이버 번역기도 인공신경망을 이용한 딥러닝 기술로 구현되어 성능이 매우 좋아졌다.
하지만 대부분의 사람이 인공지능과 머신러닝 용어를 들어본 적은 있지만 정확한 구분을 하지 못한다고 한다. 그리고 최근에 딥러닝이라는 용어가 추가되어 더욱더 헷갈릴 수 있어 간단하게 설명해보고자 한다.
인공지능은 말 그대로 컴퓨터가 사람처럼 지능을 가진 것처럼 스스로 일을 할 수 있게 하는 기술을 말한다. 과거에는 이 인공지능을 머신러닝(machine learning)이라는 기술로 대부분 구현됐었지만 최근에는 머신러닝 분야에 인공신경망을 이용한 딥러닝 기술을 적용하고 있다. 최근 성능이 좋다고 알려진 인공지능 기반의 툴들은 대부분 딥러닝을 이용해 개발되었다고 봐도 무방하다.
그리고 이러한 딥러닝 기술은 유전체 분야에도 적용되고 있는데 적용 가능하게 된 배경은 다음과 같은 3가지 이유를 들 수 있다.
첫째, 기하급수적인 유전체 분야 데이터의 증가이다. 차세대유전체해독(NGS) 장비의 혁명으로 인해 기존의 생어 해독에 비해 100만 분의 1로 가격이 하락했으며 이로 인해 유전체 데이터는 2년마다 2배씩 증가하고 있다고 한다. 둘째, 엔비디아(NVIDIA)의 GPU의 성능이다. CPU에 비해 가격 대비 성능이 200배 이상 월등히 앞서 있으며 이를 계산장비로 활용해 빅데이터 분석을 위한 딥러닝에 최적화 되어있다. 마지막으로 딥러닝에 접근할 기회가 많아지고 이를 구현하는 방식이 매우 쉬워졌기 때문이다. 이미 오픈소스로 딥러닝 기술을 구현하는데 필요한 소스 라이브러리가 대부분 공개되어 있기 때문이다.
이런 요인으로 최근, 특히 데이터가 많이 모이는 유전체/오믹스 분야에서 이 딥러닝 기술의 적용은 기존에 해결하지 못했던 문제들을 많이 해결할 수 있을 것으로 보는 시각이 많아졌다. 이를 보여주는 예시가 앞서 언급한 구글과 브로드 연구소의 유전체 데이터 분석 툴에 딥러닝 기술을 적용한 것이다. 그리고 이러한 트렌드는 더욱 더 확산되어 다양한 생명정보 분야로 적용될 것으로 보인다.
특히 암 환자 빅 데이터(유전체, 단백체, 영상 및 슬라이드 이미지, 임상 정보 등)의 경우 수만 명의 정보가 이미 축적되어 있어 이 분야에서 가장 먼저 성과가 예상이 된다.

2016년 1월 전 미국 부통령이었던 부 바이던(Beau Biden)은 Cancer Moonshot을 제안했고 이를 통해 연구자, 정부, 기업들이 협력하여 암 환자 데이터 공유를 위한 거대한 프로젝트가 시작되었다. 그리고 이 정책적 근거로 미국 국립암연구소(NCI)에 의해 펀딩된 모든 유전체 데이터들을 통합해 GDC(Genome Data Commons)를 구축해 나가고 있다. 미래 의학은 빅데이터 없이는 구현하기 어렵다는 판단 아래 미국정부는 Cancer Moonshot과 PMI Oncology 프로젝트를 시작해 적어도 분자 레벨의 암 서브타입(cancer subtype)을 결정해보자는 첫 목표를 향해 방대한 암 환자 데이터를 수집하는 것이다. 그리고 이를 확장해 암 연구자들의 다양하고 복잡한 암 연구 니즈를 만족시키기 위해 가장 기초가 되는 데이터들을 제공하는 것을 목적으로 설계하고 데이터들을 생산, 관리하고 배포하고 있다.
이런 기회를 맞아 전 세계 암 연구자와 인공지능 및 딥러닝 전문가들은 서로 협력해 이 데이터를 이용한 새로운 진단법 및 치료법을 개발하기 위해 노력 중에 있으며 머지않아 딥러닝 & 암 오믹스 빅데이터를 기반한 수많은 연구성과들이 나올 것으로 예상된다.
이처럼 다가오는 미래 의학 그리고 임상 빅데이터 시대를 준비하기 위해 연구 공동체가 합의하고 이를 기반으로 정부는 정책적으로 지지하고 지원하기 위해 정책을 수립하고 이렇게 결정된 계획들이 엄격히 실행 되어 가는 미국의 행보가 멋지고 부럽기도 하다. 우리나라도 국내 연구소 및 회사에서 암 진단과 치료제를 개발함에 있어 자유롭게 빅데이터를 활용할 수 있도록 국가 연구비나 임상시험을 통해 생산되는 암 환자 빅데이터들을 제대로 관리하고 연구자들에게 배포할 수 있는 데이터 센터 구축이 시급해 보인다.
출처
https://www.skynettoday.com/briefs/google-deepvariant/
https://ai.googleblog.com/2017/12/deepvariant-highly-accurate-genomes.html
https://www.wired.com/story/google-is-giving-away-ai-that-can-build-your-genome-sequence/
https://www.broadinstitute.org/blog/machine-learning-deep-learning-and-ai-oh-my